进程与线程
进程
我们都知道计算机的核心是CPU,它承担了所有的计算任务,而操作系统是计算机的管理者,它负责任务的调度,资源的分配和管理,
统领整个计算机硬件;应用程序是具有某种功能的程序,程序是运行于操作系统之上的。
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用
程序运行的载体。进程是一种抽象的概念,从来没有统一的标准定义。进程一般由程序,数据集合和进程控制块三部分组成。程序用于描述
进程要完成的功能,是控制进程执行的指令集;数据集合是程序在执行时所需要的数据和工作区;程序控制块包含进程的描述信息和控制信息
是进程存在的唯一标志
进程具有的特征:
动态性:进程是程序的一次执行过程,是临时的,有生命期的,是动态产生,动态消亡的;
并发性:任何进程都可以同其他进行一起并发执行;
独立性:进程是系统进行资源分配和调度的一个独立单位;
结构性:进程由程序,数据和进程控制块三部分组成
线程
在早期的操作系统中并没有线程的概念,进程是拥有资源和独立运行的最小单位,也是程序执行的最小单位。任务调度采用的是时间片
轮转的抢占式调度方式,而进程是任务调度的最小单位,每个进程有各自独立的一块内存,使得各个进程之间内存地址相互隔离。
后来,随着计算机的发展,对CPU的要求越来越高,进程之间的切换开销较大,已经无法满足越来越复杂的程序的要求了。于是就发明
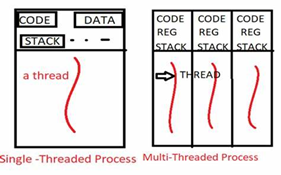
了线程,线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位。一个进程可以有一个或
多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。一个标准的线程由线程ID,当前指令指针PC,寄存器和堆栈组
成。而进程由内存空间(代码,数据,进程空间,打开的文件)和一个或多个线程组成。
进程与线程的区别
线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;
一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线
进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段,数据集,堆等)及一些进程级的资源(如打开文件和信
号等),某进程内的线程在其他进程不可见;
- 调度和切换:线程上下文切换比进程上下文切换要快得多
线程和进程关系示意图


总之,线程和进程都是一种抽象的概念,线程是一种比进程还小的抽象,线程和进程都可用于实现并发。
在早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位,它相当于
一个进程里只有一个线程,进程本身就是线程。所以线程有时被称为轻量级进程
后来,随着计算机的发展,对多个任务之间上下文切换的效率要求越来越高,就抽象出一个更小的概念-线程,一般一个进程会有多个
(也可以是一个)线程。

任务调度
大部分操作系统的任务调度是采用时间片轮转的抢占式调度方式,也就是说一个任务执行一小段时间后强制暂停去执行下一个任务,每个
任务轮流执行。任务执行的一小段时间叫做时间片,任务正在执行时的状态叫运行状态,任务执行一段时间后强制暂停去执行下一个任务,被
暂停的任务就处于就绪状态,等待下一个属于它的时间片的到来。这样每个任务都能得到执行,由于CPU的执行效率非常高,时间片
非常短,在各个任务之间快速地切换,给人的感觉就是多个任务在“同时进行”,这也就是我们所说的并发

为何不使用多进程而是使用多线程?
线程廉价,线程启动比较快,退出比较快,对系统资源的冲击也比较小。而且线程彼此分享了大部分核心对象(File Handle)的拥有权
如果使用多重进程,但是不可预期,且测试困难
进程是资源分配的最小单位,线程是CPU调度的最小单位
线程和进程有什么区别?可以说是程序员必须准备的一道高频面试题。
相信不少程序员在面试算法或开发岗位时都遇到过这个问题。尽管这个问题似乎每个接触过计算机操作系统的人都应该懂,但是如何能回答好这个问题却十分考验程序员的水平。
为了能够给出一个全面而深入的答案,首先我们要理解线程的概念,以及为什么需要线程编程。
什么是线程呢?
网上一般是这样定义的:线程(thread)是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。
这么说,你听懂了吗?我觉得这样的定义纯粹是自说自话:新手看完了一脸懵,老鸟看完了不以为然。我们还是用“非专业”的外行话来解释一下吧。

假设你经营着一家物业管理公司。最初,业务量很小,事事都需要你亲力亲为。给老张家修完暖气管道,立马再去老李家换电灯泡——这叫单线程,所有的工作都得顺序执行。
后来业务拓展了,你雇佣了几个工人,这样,你的物业公司就可以同时为多户人家提供服务了——这叫多线程,你是主线程。
工人们使用的工具,是物业管理公司提供的,这些工具由大家共享,并不专属于某一个人——这叫多线程资源共享。
工人们在工作中都需要管钳,可是管钳只有一把——这叫冲突。解决冲突的办法有很多,比如排队等候、等同事用完后的微信通知等——这叫线程同步。
你给工人布置任务——这叫创建线程。之后你还得要告诉他,可以开始了,不然他会一直停在那儿不动——这叫启动线程(start)。
如果某个工人(线程)的工作非常重要,你(主线程)也许会亲自监工一段时间,如果不指定时间,则表示你会一直监工到该项工作完成——这叫线程参与(join)。
业务不忙的时候,你就在办公室喝喝茶。下班时间一到,你群发微信,所有的工人不管手头的工作是否完成,都立马撂下工具,跟你走人。因此如果有必要,你得避免不要在工人正忙着的时候发下班的通知——这叫线程守护属性设置和管理(daemon)。
再后来,你的公司规模扩大了,同时为很多生活社区服务,你在每个生活社区设置了分公司,分公司由分公司经理管理,运营机制和你的总公司几乎一模一样——这叫多进程,总公司叫主进程,分公司叫子进程。
总公司和分公司,以及各个分公司之间,工具都是独立的,不能借用、混用——这叫进程间不能共享资源。各个分公司之间可以通过专线电话联系——这叫管道。各个分公司之间还可以通过公司公告栏交换信息——这叫进程间共享内存。另外,各个分公司之间还有各种协同手段,以便完成更大规模的作业——这叫进程间同步。分公司可以跟着总公司一起下班,也可以把当天的工作全部做完之后再下班——这叫守护进程设置。
进程有什么用?
进程可以说是一个“执行中的程序”。程序是指令、数据及其组织形式的描述,是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程。
有了线程技术,我们就可以在一个进程中创建多个线程,让它们在“同一时刻”分别去做不同的工作了。这些线程共享同一块内存,线程之间可以共享对象、资源,如果有冲突或需要协同,还可以随时沟通以解决冲突或保持同步。
不过,多线程技术不是万金油,它有一个致命的缺点:在一个进程内,不管你创建了多少线程,它们总是被限定在一颗CPU内,或者多核CPU的一个核内。这意味着,多线程在宏观上是并行的,在微观上则是分时切换串行的,多线程编程无法充分发挥多核计算资源的优势。这也是使用多线程做任务并行处理时,线程数量超过一定数值后,线程越多速度反倒越慢的原因。
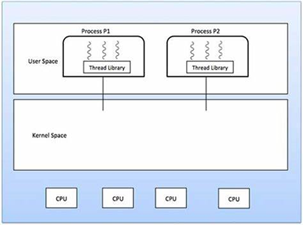
多进程技术正好弥补了多线程编程的不足,我们可以在每一颗CPU上,或者多核CPU的每一个核上启动一个进程,如果有必要,还可以在每个进程内再创建适量的线程,最大限度地使用计算资源解决问题。因为不在同一块内存区域内,和线程相比,进程间的资源共享、通信、同步等,都要麻烦得多,受到的限制也更多。
协程
子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
多进程
要让Python程序实现多进程(multiprocessing),我们先了解操作系统的相关知识。
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
1 | # multiprocessing.py |
运行结果如下:
1 | Process (876) start... |
由于Windows没有fork调用,上面的代码在Windows上无法运行。由于Mac系统是基于BSD(Unix的一种)内核,所以,在Mac下运行是没有问题的,推荐大家用Mac学Python!
有了fork调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,常见的Apache服务器就是由父进程监听端口,每当有新的http请求时,就fork出子进程来处理新的http请求。
multiprocessing
如果你打算编写多进程的服务程序,Unix/Linux无疑是正确的选择。由于Windows没有fork调用,难道在Windows上无法用Python编写多进程的程序?
由于Python是跨平台的,自然也应该提供一个跨平台的多进程支持。multiprocessing模块就是跨平台版本的多进程模块。
multiprocessing模块提供了一个Process类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
1 | from multiprocessing import Process |
执行结果如下:
1 | Parent process 928. |
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动,这样创建进程比fork()还要简单。
join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
1 | from multiprocessing import Pool |
执行结果如下:
1 | Parent process 669. |
代码解读:
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
请注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。如果改成:
1 | p = Pool(5) |
就可以同时跑5个进程。
由于Pool的默认大小是CPU的核数,如果你不幸拥有8核CPU,你要提交至少9个子进程才能看到上面的等待效果。
进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
1 | from multiprocessing import Process, Queue |
运行结果如下:
1 | Put A to queue... |
在Unix/Linux下,multiprocessing模块封装了fork()调用,使我们不需要关注fork()的细节。由于Windows没有fork调用,因此,multiprocessing需要“模拟”出fork的效果,父进程所有Python对象都必须通过pickle序列化再传到子进程去,所有,如果multiprocessing在Windows下调用失败了,要先考虑是不是pickle失败了。
小结
在Unix/Linux下,可以使用fork()调用实现多进程。
要实现跨平台的多进程,可以使用multiprocessing模块。
进程间通信是通过Queue、Pipes等实现的。
多线程
多任务可以由多进程完成,也可以由一个进程内的多线程完成。
我们前面提到了进程是由若干线程组成的,一个进程至少有一个线程。
由于线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python也不例外,并且,Python的线程是真正的Posix Thread,而不是模拟出来的线程。
Python的标准库提供了两个模块:thread和threading,thread是低级模块,threading是高级模块,对thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行:
1 | import time, threading |
执行结果如下:
1 | thread MainThread is running... |
由于任何进程默认就会启动一个线程,我们把该线程称为主线程,主线程又可以启动新的线程,Python的threading模块有个current_thread()函数,它永远返回当前线程的实例。主线程实例的名字叫MainThread,子线程的名字在创建时指定,我们用LoopThread命名子线程。名字仅仅在打印时用来显示,完全没有其他意义,如果不起名字Python就自动给线程命名为Thread-1,Thread-2……
Lock
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
来看看多个线程同时操作一个变量怎么把内容给改乱了:
1 | import time, threading |
我们定义了一个共享变量balance,初始值为0,并且启动两个线程,先存后取,理论上结果应该为0,但是,由于线程的调度是由操作系统决定的,当t1、t2交替执行时,只要循环次数足够多,balance的结果就不一定是0了。
原因是因为高级语言的一条语句在CPU执行时是若干条语句,即使一个简单的计算:
1 | balance = balance + n |
也分两步:
- 计算
balance + n,存入临时变量中; - 将临时变量的值赋给
balance。
也就是可以看成:
1 | x = balance + n |
由于x是局部变量,两个线程各自都有自己的x,当代码正常执行时:
1 | 初始值 balance = 0 |
但是t1和t2是交替运行的,如果操作系统以下面的顺序执行t1、t2:
1 | 初始值 balance = 0 |
究其原因,是因为修改balance需要多条语句,而执行这几条语句时,线程可能中断,从而导致多个线程把同一个对象的内容改乱了。
两个线程同时一存一取,就可能导致余额不对,你肯定不希望你的银行存款莫名其妙地变成了负数,所以,我们必须确保一个线程在修改balance的时候,别的线程一定不能改。
如果我们要确保balance计算正确,就要给change_it()上一把锁,当某个线程开始执行change_it()时,我们说,该线程因为获得了锁,因此其他线程不能同时执行change_it(),只能等待,直到锁被释放后,获得该锁以后才能改。由于锁只有一个,无论多少线程,同一时刻最多只有一个线程持有该锁,所以,不会造成修改的冲突。创建一个锁就是通过threading.Lock()来实现:
1 | balance = 0 |
当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try...finally来确保锁一定会被释放。
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
多核CPU
如果你不幸拥有一个多核CPU,你肯定在想,多核应该可以同时执行多个线程。
如果写一个死循环的话,会出现什么情况呢?
打开Mac OS X的Activity Monitor,或者Windows的Task Manager,都可以监控某个进程的CPU使用率。
我们可以监控到一个死循环线程会100%占用一个CPU。
如果有两个死循环线程,在多核CPU中,可以监控到会占用200%的CPU,也就是占用两个CPU核心。
要想把N核CPU的核心全部跑满,就必须启动N个死循环线程。
试试用Python写个死循环:
1 | import threading, multiprocessing |
启动与CPU核心数量相同的N个线程,在4核CPU上可以监控到CPU占用率仅有160%,也就是使用不到两核。
即使启动100个线程,使用率也就170%左右,仍然不到两核。
但是用C、C++或Java来改写相同的死循环,直接可以把全部核心跑满,4核就跑到400%,8核就跑到800%,为什么Python不行呢?
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
不过,也不用过于担心,Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。

